1. java代码是怎么运行的
Java将运行时的内存区域划分为五个部分,如下图所示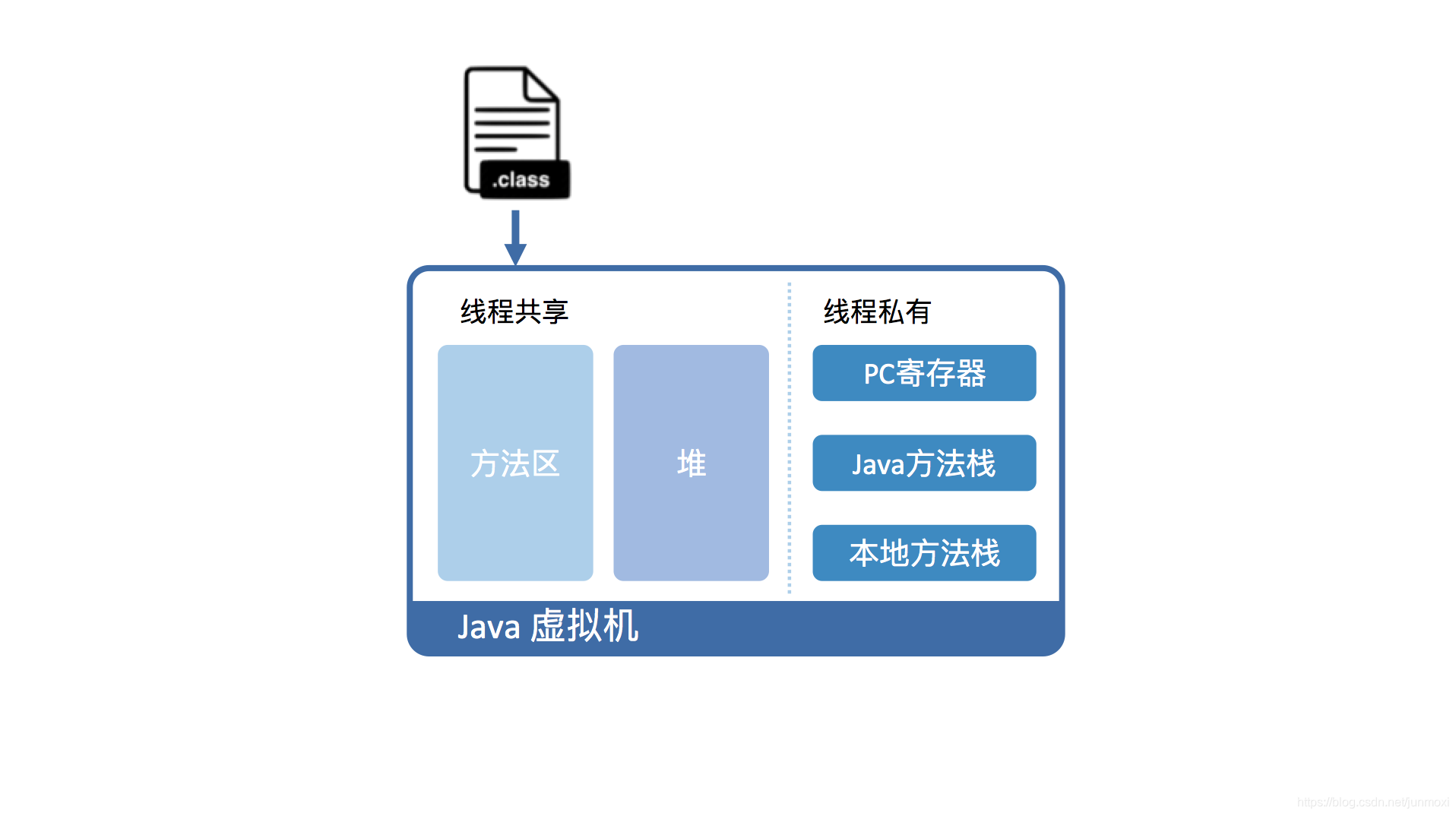
从虚拟机的视角来看
执行java代码首先需要将它编译后的class文件加载到虚拟机中,加载后的Java类会被存放到
方法区中,实际运行时,虚拟机会执行方法区中的代码。在运行过程中,每当调用进入一个Java方法,java虚拟机就会在当前线程的Java方法栈中生成一个栈帧,用以存放该方法的局部变量和字节码操作数,当退出当前执行方法时,无论方法是正常返回还是异常返回,Java虚拟机均会弹出当前栈帧,并将之舍弃。
从硬件的视角来看
Java字节码无法直接执行,因此Java虚拟机需要将字节码翻译为机器码执行。在
Hotspot虚拟机中,此翻译过程有两种方式:
- 解释执行:逐条将字节码翻译为机器码并执行,优点:无需等待
- 即时翻译:将一个方法中包含的字节码全部翻译成机器码后再执行。优点:实际运行速度快
Hotspot内置了多个即时编译器,C1,C2,Graal
- C1:又被叫做Client编译器,面向的是对启动性能有要求的GUI程序
- C2:又被叫做Server编译器,面向的是对峰值性能有要求的服务端程序
从Java7之后,
Hotspot采用了分层编译模式:热点代码会被C1进行编译,而热点中的热点代码会进一步被C2进行编译。Hotspot会根据CPU数量及编译线程数目,按1:2的比例配置给C1和C2。
2. 类的加载过程
java虚拟机将字节流转化为java类的过程分为三个部分:加载、链接、初始化。
加载:加载是指查找字节流并以此创建类的过程。加载需要借助类加载器,在java虚拟机中类加载器采用双亲委派模型,即受到类加载请求,会先将请求交给父加载器加载,如果父加载器不能加载才由自己进行加载。
链接:链接是指将创建的类合并至java虚拟机中,此过程分为三个部分:验证、准备、解析,其中解析过程是非必须的。
初始化:初始化则是为标记为常量值的字段赋值,以及执行
类的初始化何时会被触发呢?JVM 规范枚举了下述多种触发情况:
- 当虚拟机启动时,初始化用户指定的主类;
- 当遇到用以新建目标类实例的 new 指令时,初始化 new 指令的目标类;
- 当遇到调用静态方法的指令时,初始化该静态方法所在的类;
- 当遇到访问静态字段的指令时,初始化该静态字段所在的类;
- 子类的初始化会触发父类的初始化;
- 如果一个接口定义了 default 方法,那么直接实现或者间接实现该接口的类的初始化,会触发该接 口的初始化;
- 使用反射 API 对某个类进行反射调用时,初始化这个类;
- 当初次调用 MethodHandle 实例时,初始化该 MethodHandle 指向的方法所在的类。
根据这个特性,我们可以实现单例的延迟初始化
1 | public class Singleton { |
用命令查看类加载的先后顺序
1 | // 编译 |
3. JVM是如何处理异常的
在编译生成的字节码中,都有一个异常表,异常表中每一个条目对应一个异常处理器,并且由from指针,to指针,target指针和type(异常捕获类型)组成。from和to指针标识了该异常的监控范围(也就是try代码块所覆盖的范围),而target指针则指向了异常处理器的起始位置(也就是catch代码块位置)
当程序触发异常时
当程序触发异常时,java虚拟机会从上至下遍历异常表中的条目,当触发异常的字节码索引在某个异常表条目的监控的范围之内,则会判断抛出的异常与该条目要捕获的异常是否匹配,如果匹配,Java虚拟机会将控制流转向该条目target指针所指向的字节码。如果遍历整个异常条目仍未匹配异常处理器,那么它会弹出当前方法对应的栈帧,并且在调用者用重复上诉操作,在最坏的情况,Java虚拟机需要遍历当前线程Java栈的上所有方法的异常表。
finally代码块如果保证必须执行的
Java编译器会复制finally块中的内容,分别放到try-catch块的正常执行路径和异常执行路径出口中。
为什么抛异常很耗费性能
JVM在构造异常实例时需要生成该异常的栈轨迹。这个操作会逐一访问当前线程的栈帧,并且记录下各种调试信息,包括栈帧所指向方法的名字,方法所在的类名、文件名,以及在代码中的第几行触发该异常等信息。
Supressed 异常
如果 catch 代码块捕获了异常,并且触发了另一个异常,那么 finally 捕获并且重抛的异常是哪个呢?答案是后者。也就是说原本的异常便会被忽略掉,这对于代码调试来说十分不利。为此Java 7 引入了 Supressed 异常来解决这个问题。这个新特性允许开发人员将一个异常附于另一个异常之上。因此,抛出的异常可以附带多个异常的信息。
try-with-resources
主要是为了精简资源打开关闭的用法。程序可以在 try 关键字后声明并实例化实现了 AutoCloseable 接口的类,编译器将自动添加对应的 close() 操作。在声明多个 AutoCloseable 实例的情况下,编译生成的字节码类似于上面手工编写代码的编译结果。与手工代码相比,try-with-resources 还会使用 Supressed 异常的功能,来避免原异常“被消失”
4. JVM是如何进行反射调用的
在默认情况下,方法的反射调用为委派实现,委派给本地实现来进行方法调用。在调用超过 15 次之后,委派实现便会将委派对象切换至动态实现。这个动态实现的字节码是自动生成的,它将直接使用 invoke 指令来调用目标方法。
反射调用的开销
- 避免返回数组
getMethod+为代表的查找方法操作,会返回查找得到结果的一份拷贝。因此,我们应当避免在热点代码中使用返回+Method+数组的+getMethods+或者+getDeclaredMethods+方法,以减少不必要的堆空间消耗。
- 避免自动拆箱装箱
由于变长参数会被编译器自动生成一个Object数组,而Object数据是不能存储基本数据类型的,所以这里就需要对int类型的进行自动装箱,默认int缓存范围为[-128~127],当数值在这个范围之内就会返回缓存的Integer对象,避免新建Integer对象,所以我们可以将这个缓存的范围扩大至覆盖 128(对应参数 -Djava.lang.Integer.IntegerCache.high=128
开销总结
方法的反射调用会带来不少性能开销,原因主要有三个:变长参数方法导致的 Object 数组,基本类型的自动装箱、拆箱,还有最重要的方法内联
方法内联
方法内联指的是编译器在编译一个方法时,将某个方法调用的目标方法也纳入编译范围内,并用其返回值替代原方法调用这么个过程。