自定义Referer拦截器
1 | public class RefererInterceptor extends HandlerInterceptorAdapter { |
配置白名单Referer域名
1 |
|
yml配置
1 | referer: |
1 | public class RefererInterceptor extends HandlerInterceptorAdapter { |
1 |
|
1 | referer: |
1 | docker pull consul:latest |
- –net=host docker参数, 使得docker容器越过了net namespace的隔离,免去手动指定端口映射的步骤
- -server consul支持以server或client的模式运行, server是服务发现模块的核心, client主要用于转发请求
- -advertise 将本机私有IP传递到consul
- -retry-join 指定要加入的consul节点地址,失败后会重试, 可多次指定不同的地址
- -client 指定consul绑定在哪个client地址上,这个地址可提供HTTP、DNS、RPC等服务,默认是>127.0.0.1
- -bind 绑定服务器的ip地址;该地址用来在集群内部的通讯,集群内的所有节点到地址必须是可达的,>默认是0.0.0.0
allow_stale 设置为true则表明可从consul集群的任一server节点获取dns信息, false则表明每次请求都会>经过consul的server leader- -bootstrap-expect 数据中心中预期的服务器数。指定后,Consul将等待指定数量的服务器可用,然后>启动群集。允许自动选举leader,但不能与传统-bootstrap标志一起使用, 需要在server模式下运行。
- -data-dir 数据存放的位置,用于持久化保存集群状态
- -node 群集中此节点的名称,这在群集中必须是唯一的,默认情况下是节点的主机名。
- -config-dir 指定配置文件,当这个目录下有 .json 结尾的文件就会被加载,详细可参考https://www.consul.io/docs/agent/options.html#configuration_files
- -enable-script-checks 检查服务是否处于活动状态,类似开启心跳
- -datacenter 数据中心名称
- -ui 开启ui界面
- -join 指定ip, 加入到已有的集群中
consul11 | docker run --name consul1 -d -p 8500:8500 -p 8300:8300 -p 8301:8301 -p 8302:8302 -p 8600:8600 consul agent -server -bootstrap-expect 2 -ui -bind=0.0.0.0 -client=0 .0.0.0 |
端口详解
consul1查看consul1的ip地址
1 | docker inspect --format='{{.NetworkSettings.IPAddress}}' consul1 |
开启第二个节点(端口8501),并加入到 consul1
1 | docker run --name consul2 -d -p 8501:8500 consul agent -server -ui -bind=0.0.0.0 -client=0.0.0.0 -join 172.17.0.4 |
开启第三个节点(端口8502),并加入到consul1‘
1 | docker run --name consul3 -d -p 8502:8500 consul agent -server -ui -bind=0.0.0.0 -client=0.0.0.0 -join 172.17.0.4 |
1 | docker exec -it consul1 consul members |
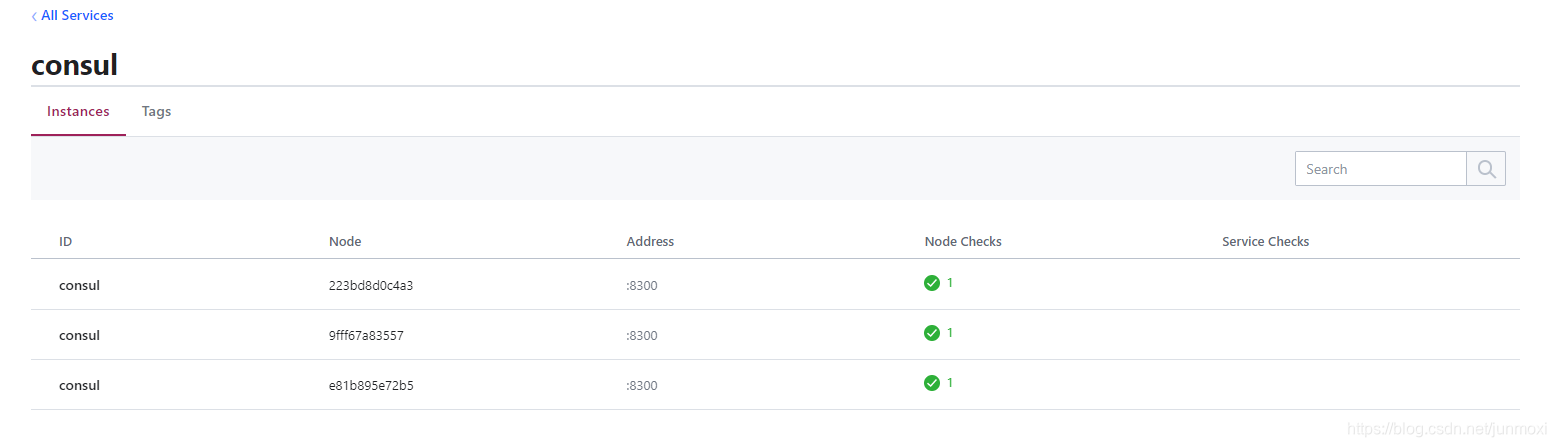
我们看到集群里有三个节点
我们可以打开浏览器: http://localhost:8500 来查看整个集群的信息
go语言里面没有while,所以实现循环都是使用for
无限循环
1 | for { |
条件循环
1 | for i:=0; i <10 ; i++{ |
跟其他语言一样,判断有大于(>) 、小于(<) 、等于(==)、不等于(!=)、大于等于(>=)、小于等于(<=)
1 | if i>10 { |
1 | switch a { |
定义常量使用 const 关键字
1 | const a int = 1 //必须要赋初值 |
全局变量,全局变量是在函数外定义并且必须要有var关键字
1 | var b int = 10 //可以不用赋初值 |
局部变量,也就是在函数中定义的变量,可以省略 var关键字
1 | var c int = 1 //最保守的写法 |
注意:在go中 _ 这个小下划线被称为废弃数,如果某个值赋值给它则此值就被废弃不再使用了
定义数组,
1 | // 定义了一个大小为10的数组 |
定义切片
1 | //切片与数组最大的不同就是,切片是变长的,它的容量可以自动扩充 |
len 是这个切片初始化时的大小
cap 是这个切片的容量,当len大于cap时,此切片就会扩容,扩容为此时的cap的2倍
1 | // 定义一个map,key为string类型,value为int类型 |
1 | type person struct{ |
1 | type Ising interface { |
go语言中只要一个实体实现了接口中的所有方法,那么这个实体就是实现了这个接口
1 | type person struct { |
go语言中一般都是把错误当成返回值给调用的函数
1 | func test(name string)(int,error){ |
当调用panic() 函数,该出错线程就会停止,而有的时候我们不想让它停止,我们可以 使用recover() 来恢复它
1 | // 不让线程终止 |
这个函数有点类似于java中的finally,都是在函数执行返回值之前做一些操作,一般都是执行一些关闭流的操作
1 | defer reader.close() |
1 | # 打印帮助信息 |

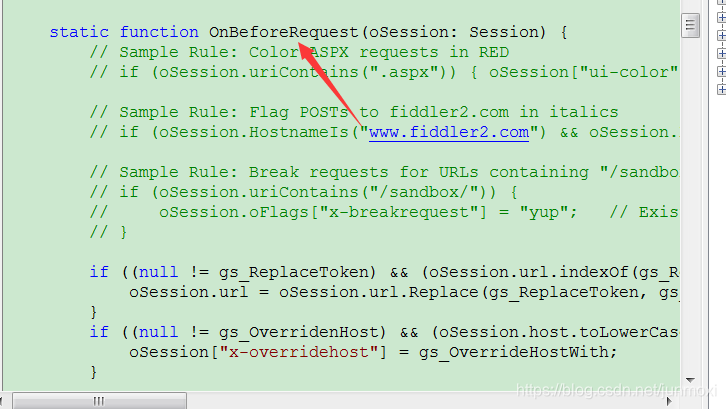
1 | if (oSession.fullUrl.Contains("http://www.baidu.com")) |
1 | if(oSession.uriContains("http://www.baidu.com")) |
1 | if(oSession.HostnameIs('www.baidu.com') && oSession.uriContains('pagewithCookie') && oSession.oRequest.headers.Contains("Cookie")) |
1 | if(oSession.HostnameIs("www.baidu.com")) |
1 | if (oSession.fullUrl.Contains("www.baidu.com/playurl/v1/") ) |
下载之后解压,并将其bin路径添加到环境变量当中
github地址: https://github.com/nsqio/nsq/releases
文档: https://nsq.io/overview/quick_start.html
1 | nsqlookupd |
它会监听两个端口:
http: 4161客户端用它来发现和管理。tcp: 4160nsqd 用它来广播
可选参数:
http-address="127.0.0.1:4161" : 监听 HTTP 客户端地址inactive-producer-timeout=5m0s: 从上次 ping 之后,生产者驻留在活跃列表中的时长 tcp-address="0.0.0.0:4160": TCP 客户端监听的地址broadcast-address: 这个 lookupd 节点的外部地址, (默认主机名) tombstone-lifetime=45s: 生产者保持 tombstoned 的时长 verbose=false: 允许输出日志 version=false: 打印版本信息1 | nsqd --lookupd-tcp-address=127.0.0.1:4160 |
它是一个守护进程,负责接收消息,传递消息给客户端,排队。 会监听两个端口:
http: 4151,tcp: 4150
1 | nsqadmin --lookupd-http-address=127.0.0.1:4161 |
它是一个Web页面,负责管理我们的消息队列, 它后面的地址即是我们在 nsqlookupd 里面
http-address参数配置的地址,nsqadmin的监听地址为4171,通过127.0.0.1:4171地址可打开NSQ的Web管理页面
Channel是消费者订阅特定Topic的一种抽象。对于发往Topic的消息,nsqd向该Topic下的所有Channel投递消息,而同一个Channel只投递一次,Channel下如果存在多个消费者,则随机选择一个消费者做投递。这种投递方式可以被用作消费者负载均衡。和Topic一样,Channel同样有永久和临时之分,永久的Channel只能通过显式删除销毁,临时的Channel在最后一个消费者断开连接的时候被销毁
Topic 就是一个通道,我们可以往这个Topic里面发送消息Channel起到一个负载均衡的作用,我们可以在一个Topic中建立多个Channel来共同消费这个Topic里面的消息。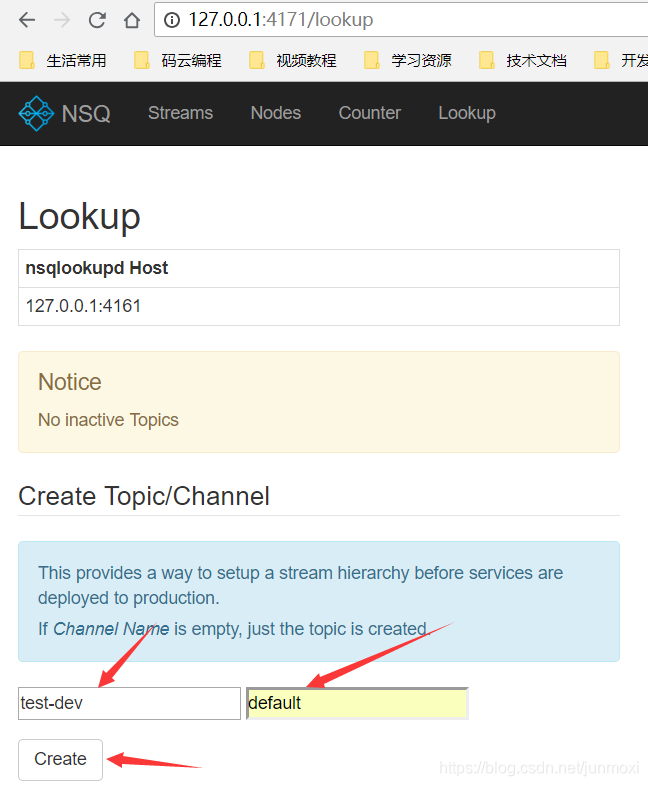
test-dev的Topic,Channel为default往通道里面发送消息
1 | curl -d 'hello world' 'http://127.0.0.1:4151/pub?topic=test-dev' |
从通道中消费消息,这里我们要指定从哪个Channel里消费,
1 | nsq_to_file --topic=test-dev -channel=default --output-dir=log --lookupd-http-address=127.0.0.1:4161 |
此时就会在当前目前下生成一个 log 文件夹,里面存放的就是我们这个Channel里的消息
安装第三方库
1 | go get -u github.com/youzan/go-nsq |
1 | package nsq |
测试
1 | package nsq |
如果你不想使用有赞的第三方库,你可以使用下面这个:
1 | go get -u github.com/nsqio/go-nsq |
代码
1 | package main |
[TOC]
AOP是一种编程范式,它主要是为了将非功能模块与业务模块分离开来,让我们更好的管理这些非功能模块。
它的使用场景有:权限控制、日志打印、事务控制、缓存控制、异常处理
- 在类上注解 @Aspect
- 如果想在方法执行前做操作,那么注解@Before注解
- 如果想在方法执行后做操作,那么注解@After注解
五大Advice注解:
注解在类上,表明此类是一个面向切面的类,同时也要记得在类上注解
@Component或者@Service将此类交给Spring管理
用来注解在方法上,表明此方法为切面方法
常用表达式有:
1 | ("@annotation(myLogger)") //只拦截有注解为@myLogger的方法 |
designators(指示器)常用的表达式
在方法执行下执行该切面方法,其用法与@Poincut类似
1 | //只拦截com.pibigstar包下,并且注解为myLogger的方法 |
在方法执行后执行该切面方法
1 | //方法结束后 |
当方法抛出异常后执行该切面方法
1 | ((myLogger)",throwing = "e") |
方法有返回值,打印出方法的返回值
1 | //方法有返回值 |
集合@Before,@After,@AfterReturning,@AfterThrowing 四大注解
1 | //集合前面四大注解 |
pom包里面只需要引入springboot starter包即可
1 | <dependencies> |
在启动类上面加上@EnableScheduling即可开启定时
1 |
|
定时任务1:
1 |
|
定时任务2:
1 |
|
结果如下:
1 | this is scheduler task runing 0 |
参数说明
@Scheduled参数可以接受两种定时的设置,一种是我们常用的cron=”*/6 * * * * ?”
,另一种是 fixedRate = 6000,两种都表示每隔六秒打印一下内容。
fixedRate 说明
@Scheduled(fixedRate = 6000) :上一次开始执行时间点之后6秒再执行
@Scheduled(fixedDelay = 6000) :上一次执行完毕时间点之后6秒再执行
@Scheduled(initialDelay=1000, fixedRate=6000) :第一次延迟1秒后执行,之后按fixedRate的规则每6秒执行一次
环境:
https://github.com/fatedier/frp/blob/master/README_zh.md
将 frps、frps.ini 及 frps.service 放到具有公网 IP 的机器上。
将 frpc 、frpc.ini 及 frpc.service 放到处于内网环境的机器上。
frps /usr/bin/frpsfrps.ini /etc/frp/frps.inifrps.service /lib/systemd/system/frps.servicefrpc /usr/bin/frpcfrpc.ini /etc/frp/frpc.inifrpc.service /lib/systemd/system/frpc.service下载
1 | https://github.com/fatedier/frp/releases |
解压
1 | tar -zxvf frp_0.28.2_linux_amd64.tar.gz |
移动位置
1 | mv frps /usr/bin/frps |
修改配置
1 | [common] |
移动位置
1 | mkdir -p /etc/frp & mv frps.ini /etc/frp/frps.ini |
ExecStart1 | [Unit] |
移动位置
1 | mv frps.service /lib/systemd/system/frps.service |
启动
1 | # 注册系统服务 |
下载
1 | https://github.com/fatedier/frp/releases |
移动文件
1 | mv frpc /usr/bin/frpc |
修改配置文件
1 | [common] |
将 blog.pibigstar.com的域名 A 记录解析到 我们公网IP地址: x.x.x.x
通过浏览器访问 http://blog.pibigstar.com:8080 即可访问到处于内网机器上的 web 服务。
ssh连接ssh -oPort=6000 root@139.189.65.203
移动位置
1 | mkdir -p /etc/frp & mv frpc.ini /etc/frp/frpc.ini |
1 | [Unit] |
移动位置
1 | mv frpc.service /lib/systemd/system/frpc.service |
启动
1 | # 注册系统服务 |
[TOC]
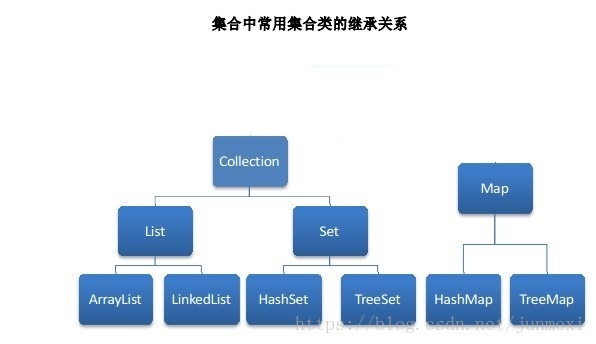
java集合类分为collection 和 map两类
Collection
List(有序、可重复)
Set(无序、不可重复)
Queue(队列,先进先出)
常用队列操作方法:
1 | void add(Object e);//将指定元素加入此队列的尾部。 |
Map
java实现多线程的两种方式:继承 Thread 类和实现 Runnable 接口
多个进程或线程同时(或着说在同一段时间内)访问同一资源会产生并发问题。
具体详细内容可点击这里查看
临界区用来表示一种公共资源或者说是共享数据,可以被多个线程使用。但是每一次,只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源,就必须等待。
阻塞和非阻塞通常用来形容多线程间的相互影响。比如一个线程占用了临界区资源,那么其它所有需要这个资源的线程就必须在这个临界区中进行等待,等待会导致线程挂起。这种情况就是阻塞。
此时,如果占用资源的线程一直不愿意释放资源,那么其它所有阻塞在这个临界区上的线程都不能工作。阻塞是指线程在操作系统层面被挂起。阻塞一般性能不好,需大约8万个时钟周期来做调度。
非阻塞则允许多个线程同时进入临界区。
死锁是进程死锁的简称,是指多个进程循环等待他方占有的资源而无限的僵持下去的局面。
假设有两个线程1、2,它们都需要资源 A/B,假设1号线程占有了 A 资源,2号线程占有了 B 资源;由于两个线程都需要同时拥有这两个资源才可以工作,为了避免死锁,1号线程释放了 A 资源占有锁,2号线程释放了 B 资源占有锁;此时 AB 空闲,两个线程又同时抢锁,再次出现上述情况,此时发生了活锁。
简单类比,电梯遇到人,一个进的一个出的,对面占路,两个人同时往一个方向让路,来回重复,还是堵着路。
如果线上应用遇到了活锁问题,恭喜你中奖了,这类问题比较难排查。
饥饿是指某一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行。
一般都是通过加锁进行实现。
1 | public class Test{ |
1 | public class Test{ |
1 | public class Test{ |
1 | public class Test{ |
Lock能实现synchronized完成的所以功能,不同点是:Lock有比synchronize更精确的线程语义和更好的性能,synchronize会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放。Lock还有更强大的功能,例如,它的tryLock方法可以非阻塞方式去拿锁。
1 | final Lock lock = new ReentrantLock(); |
通过上面的介绍,完全可以开发一个多线程的程序,为什么还要引入线程池呢。主要是因为上述单线程方式存在以下几个问题:
四种线程池的使用
newCachedThreadPool :创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
1 | ExecutorService cachedThreadPool = Executors.newCachedThreadPool(); |
newFixedThreadPool :创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
1 | ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3); |
newScheduledThreadPool:创建一个定长线程池,支持定时及周期性任务执行
1 | ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5); |
newSingleThreadExecutor:创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
1 | ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor(); |
对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object
类中的。 sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态
依然保持者,当指定的时间到了又会自动恢复运行状态。
在调用sleep()方法的过程中,线程不会释放对象锁。
而当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对
此对象调用notify()方法或notifyAll()方法后本线程才进入对象锁定池准备获取对象锁进入运行状态。
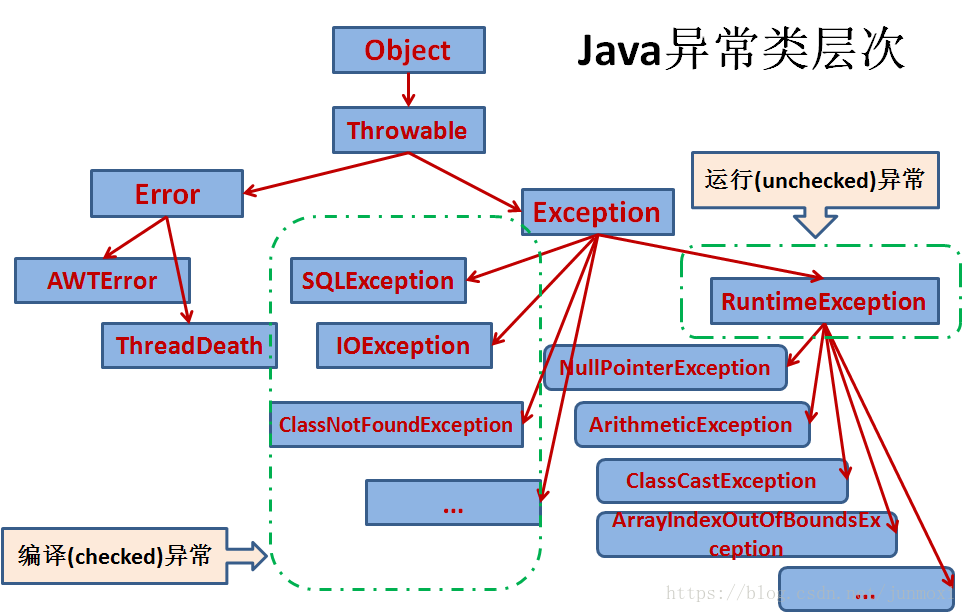
一般都是通过try···catch···finally 进行处理
1 | try{ |
需要注意的是:
1 | public int test(){ |
throws 抛到上一层(用在方法上)
1 | public void foo() throws SQLException, IOException,ClassNotFloundException |
throw 抛出异常 (用在方法内部)
1 | public void save(User user){ |
反射是框架设计的灵魂
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法.所以先要获取到每一个字节码文件对应的Class类型的对象.
以上的总结就是什么是反射
反射就是把java类中的各种成分映射成一个个的Java对象
例如:一个类有:成员变量、方法、构造方法、包等等信息,利用反射技术可以对一个类进行解剖,把个个组成部分映射成一个个对象。
(其实:一个类中这些成员方法、构造方法、在加入类中都有一个类来描述)
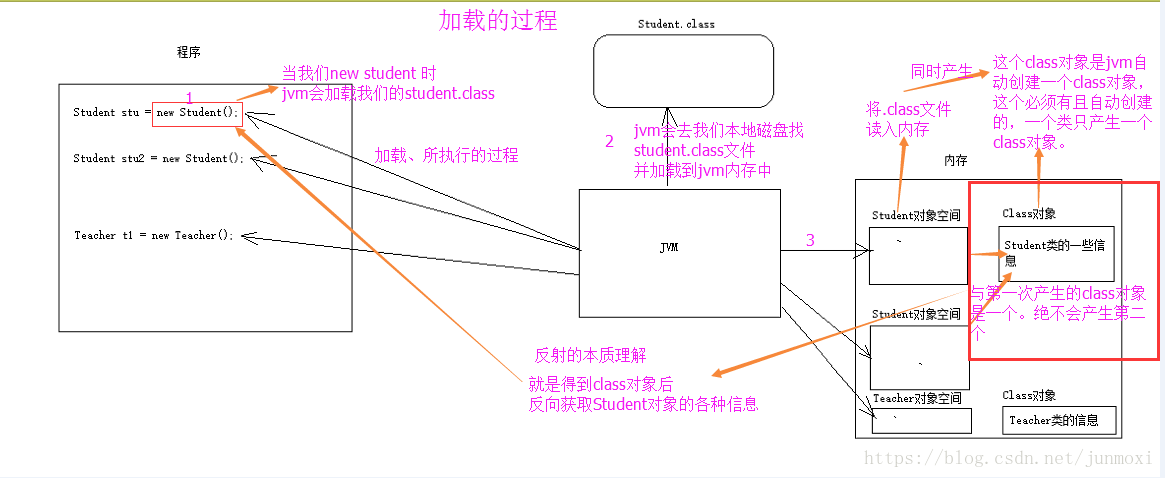
如图是类的正常加载过程:反射的原理在与class对象。
熟悉一下加载的时候:Class对象的由来是将class文件读入内存,并为之创建一个Class对象。
Object ——> getClass();
1 | Student stu1 = new Student();//产生一个Student对象,一个Class对象。 |
任何数据类型(包括基本数据类型)都有一个“静态”的class属性
1 | Class stuClass2 = Student.class; |
1 | Class stuClass3 = Class.forName("fanshe.Student"); |
1 | //1.加载Class对象 |
1 | //1.获取Class对象 |
1 | //获取Class对象 |
1 | //1.获取Student对象的字节码 |
单例模式可以保证系统中一个类只有一个实例。即一个类只有一个对象实例
1 | public class Singleton{ |
对于饿汉模式来说,这种写法已经很‘perfect’了,
唯一的缺点就是,由于instance的初始化是在类加载时进行的,
类加载是由ClassLoader来实现的,如果初始化太早,就会造成资源浪费
1 | public class Singleton{ |
这种写法在单线程的时候是没问题的。
但是,当有多个线程一起工作的时候,如果有两个线程同时运行到 if (instance == null),
都判断为null(第一个线程判断为空之后,并没有继续向下执行,当第二个线程判断的时候instance依然为空)
最终两个线程就各自会创建一个实例出来。这样就破环了单例模式 实例的唯一性,
双重检查模式
1 | public class Singleton{ |
静态内部类实现
1 | public class Singleton { |
它利用了ClassLoader来保证了同步,同时又能让开发者控制类加载的时机。从内部看是一个饿汉式的单例,但是从外部看来,又的确是懒汉式的实现
具体内容请移步: