查看内存
1 | free -h |
释放内存
可用内存为:free + buff/caches的
1 | # 写缓存到文件系统 |
1 | free -h |
可用内存为:free + buff/caches的
1 | # 写缓存到文件系统 |
目前默认的内核都是 3.10的,我们需要升级到4.4
- 查看内核版本
1 | uname -r |
升级
1 | rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org |
再次查看当前内核
1 | uname -r |
移除无用内核
1 | yum remove -y kernel* |
有时候可能中文显示会出现问题,这里我们将字体编码改为UTF-8
1 | cat >> /etc/profile <<EOF |
刷新生效
1 | source /ect/profile |
查看进行限制
1 | cat /etc/security/limits.d/20-nproc.conf_bk |
修改限制
你可以加大限制,也可以改为
unlimited,让其不限制进程
1 | vim /etc/security/limits.d/20-nproc.conf_bk |
查看当前使用时区
1 | timedatectl | grep "Time zone" |
修改时区
这里我们修改为上海的时区
1 | ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime |
我们可以增大或减小文件的打开数,来优化我们系统的运行效率
1 | vim /etc/serurity/limits.conf |
将文件添加到/etc/profile中
1 | cat >> /etc/profile <<EOF |
使命令生效
1 | source /etc/profile |
查看日志
登录,登出之后在
/var/log/history中就可以看到以用户命名的文件夹,进入之后就会显示所有的日志操作
压缩日志,将compress的注释删掉
1 | vim /etc/logrotate.conf |
添加列
1 | ALTER TABLE 表名 add COLUMN 列名 VARCHAR(2) DEFAULT NULL COMMENT '注释'; |
删除列
1 | alter table 表名 drop column 列名; |
更新列名
1 | alter table 表名 change 列名 新列名 varchar(30); |
修改列属性
1 | alter table 表名 modify 列名 varchar(22); |
修改字段默认值
1 | alter table 表名 alter 字段名 set default 1000; |
删除字段默认值
1 | alter table 表名 alter 列名 drop default; |
修改表名
1 | alter table 表名 rename to 新表名; |
转载自:https://blog.csdn.net/zhangzhebjut/article/details/25181151
在过去近十年时间里,面向对象编程大行其道,以至于在大学的教育里,老师也只会教给我们两种编程模型,面向过程和面向对象。孰不知,在面向对象思想产生之前,函数式编程已经有了数十年的历史。就让我们回顾这个古老又现代的编程模型,看看究竟是什么魔力将这个概念在21世纪的今天再次拉入我们的视野。
随着硬件性能的提升以及编译技术和虚拟机技术的改进,一些曾被性能问题所限制的动态语言开始受到关注,Python、Ruby 和 Lua 等语言都开始在应用中崭露头角。动态语言因其方便快捷的开发方式成为很多人喜爱的编程语言,伴随动态语言的流行,函数式编程也再次进入了我们的视野。
究竟什么是函数式编程呢?
在维基百科中,对函数式编程有很详细的介绍。Wiki上对Functional Programming的定义:
In computer science, functional programming is a programming paradigm that treats computation as the evaluation of mathematical functions and avoids state and mutable data.
简单地翻译一下,也就是说函数式编程是一种编程模型,他将计算机运算看做是数学中函数的计算,并且避免了状态以及变量的概念。
在函数编程中经常用到闭包,闭包是什么?它是怎么产生的及用来解决什么问题呢?先给出闭包的字面定义:闭包是由函数及其相关引用环境组合而成的实体(即:闭包=函数+引用环境)。这个从字面上很难理解,特别对于一直使用命令式语言进行编程的程序员们。
闭包只是在形式和表现上像函数,但实际上不是函数。函数是一些可执行的代码,这些代码在函数被定义后就确定了,不会在执行时发生变化,所以一个函数只有一个实例。闭包在运行时可以有多个实例,不同的引用环境和相同的函数组合可以产生不同的实例。所谓引用环境是指在程序执行中的某个点所有处于活跃状态的约束所组成的集合。其中的约束是指一个变量的名字和其所代表的对象之间的联系。那么为什么要把引用环境与函数组合起来呢?这主要是因为在支持嵌套作用域的语言中,有时不能简单直接地确定函数的引用环境。这样的语言一般具有这样的特性:
函数是一等公民(First-class value),即函数可以作为另一个函数的返回值或参数,还可以作为一个变量的值。
函数可以嵌套定义,即在一个函数内部可以定义另一个函数。
在面向对象编程中,我们把对象传来传去,那在函数式编程中,要做的是把函数传来传去,说成术语,把他叫做高阶函数。在数学和计算机科学中,高阶函数是至少满足下列一个条件的函数:
在函数式编程中,函数是基本单位,是第一型,他几乎被用作一切,包括最简单的计算,甚至连变量都被计算所取代。
函数只是一段可执行代码,编译后就“固化”了,每个函数在内存中只有一份实例,得到函数的入口点便可以执行函数了。在函数式编程语言中,函数是一等公民(First class value):第一类对象,我们不需要像命令式语言中那样借助函数指针,委托操作函数,函数可以作为另一个函数的参数或返回值,可以赋给一个变量。函数可以嵌套定义,即在一个函数内部可以定义另一个函数,有了嵌套函数这种结构,便会产生闭包问题。如:
1 | package main |
在这段程序中,函数innerfunc是函数adder的内嵌函数,并且是adder函数的返回值。我们注意到一个问题:内嵌函数innerfunc中引用到外层函数中的局部变量sum,Go会这么处理这个问题呢?先让我们来看看这段代码的运行结果:
1 | 0 0 |
注意: Go不能在函数内部显式嵌套定义函数,但是可以定义一个匿名函数。如上面所示,我们定义了一个匿名函数对象,然后将其赋值给innerfunc,最后将其作为返回值返回。
当用不同的参数调用adder函数得到(pos(i),neg(i))函数时,得到的结果是隔离的,也就是说每次调用adder返回的函数都将生成并保存一个新的局部变量sum。其实这里adder函数返回的就是闭包。
这个就是Go中的闭包,一个函数和与其相关的引用环境组合而成的实体。一句关于闭包的名言: 对象是附有行为的数据,而闭包是附有数据的行为。
闭包经常用于回调函数,当IO操作(例如从网络获取数据、文件读写)完成的时候,会对获取的数据进行某些操作,这些操作可以交给函数对象处理。
除此之外,在一些公共的操作中经常会包含一些差异性的特殊操作,而这些差异性的操作可以用函数来进行封装。看下面的例子:
1 | package main |
输出结果:
1 | [4 3 2 1] |
在上面的例子中,Process函数负责对切片(数组)数据进行操作,在操作切片(数组)时候,首先要做一些参数检测,例如指针是否为空、数组长度是否大于0等。这些是操作数据的公共操作。具体针对数据可以有自己特殊的操作,包括排序(升序、降序)、输出等。针对这些特殊的操作可以使用函数对象来进行封装。
再看下面的例子,这个例子没什么实际意义,只是为了说明闭包的使用方式。
1 | package main |
输出结果:
1 | [2 2 4 4 6] |
Data作为公共函数,然后分别定义了两个具体的特殊函数:偶数和奇数的过滤器,定义具体的操作。
上面例子中闭包的使用有点类似于面向对象设计模式中的模版模式,在模版模式中是在父类中定义公共的行为执行序列,然后子类通过重载父类的方法来实现特定的操作,而在Go语言中我们使用闭包实现了同样的效果。
其实理解闭包最方便的方法就是将闭包函数看成一个类 ,一个闭包函数调用就是实例化一个类(在Objective-c中闭包就是用类来实现的),然后就可以从类的角度看出哪些是全局变量,哪些是局部变量。例如在第一个例子中,pos和neg分别实例化了两个闭包类,在这个闭包类中有个闭包全局变量sum。所以这样就很好理解返回的结果了。
参考:
http://www.ibm.com/developerworks/cn/linux/l-cn-closure/index.html
请求
在header的Set-Cookie中记录着该值
请求
请求头带入Referer,Cookie带入pt_local_token=第一步得到的值
端口是从4000~4008之间的,不确定哪一个
referer:
返回数据
var var_sso_uin_list=
[{“account”:”Q号”,”client_type”:65793,”face_index”:144,”gender”:1,”nickname”:”Blue”,”uin”:”QQ号”,”uin_flag”:4194822}];ptui_getuins_CB(var_sso_uin_list);
请求:
请求头带入Referer,Cookie带入pt_local_token=第一步得到的值
clientkey还是在response中的header的Set-Cookie中
请求
请求头带入referer和cookie。
cookie需要带入pt_local_token、clientuin、clientkey等关键参数。
skey,uin还是在response中的header的Set-Cookie中
另外此请求返回数据中有一个URL,其实用这个URL就可以直接登录对方的QQ空间了。
URL 大概下面这样子
请求
请求头带入referer和cookie。
cookie需要带入pt_local_token
特别注意:p_skey是在response的Request的Response的Header中
我把源码放我公众号上了,喜欢研究的朋友可以去取一下,回复: QQ快速登录 即可获取
再放几个常用的接口:
接口:https://qun.qq.com/cgi-bin/qun_mgr/get_friend_list
POST请求
Header中加入cookie,cookie中带入这三个值:uin=; skey=;p_skey=
Body中带入:bkn=g_tk
g_tk是通过skey经过算法计算出来了,源码中有这个算法
接口:https://qun.qq.com/cgi-bin/qun_mgr/get_group_list
POST请求
Header中加入cookie,cookie中带入这三个值:uin=; skey=;p_skey=
Body中带入:bkn=g_tk
接口:https://qun.qq.com/cgi-bin/qun_mgr/search_group_members
POST请求
Header中加入cookie,cookie中带入这三个值:uin=; skey=;p_skey=
POST参数:bkn=;gc=群号;sort=0;st=起始位置;end=结束位置
其中end为要获取多少个,st为获取成员的起始位置
下载链接:https://pan.baidu.com/s/1iNHJKK9Ndsag_gqi2PYAkQ
提取码:72ke
1 | public class Foo { |
当我们编译后直接运行会打印出
1 | Hello, Java! |
我们知道,boolean类型在虚拟机是以int方式进行存储的,0是false,1是true,可当我们通过修改字节码的方式,让flag等于2 会发生什么,跟着我下面的步骤一起来看看吧
先编译Foo
1 | javac Foo.java |
通过字节码工具反编译
1 | java -jar asmtools.jar jdis Foo.class > Foo.jasm.1 |
修改flag的字节码
1 | awk 'NR==1, /iconst_1/{sub(/iconst_1/,"iconst_2")} 1' Foo.jasm.1 > Foo.jasm |
将jasm反编译的再次编译为class文件
1 | java -jar asmtools.jar jasm Foo.jasm |
运行Foo.class
1 | java Foo |
我们会发现只打印出了
1 | Hello, Java! |
我们发现 第二个if不成立了,第一个还是成立,这是因为当我们直接进行 if(flag) 是按java虚拟机的翻译就是 当flag不等于0时则成立 而 if(flag==true) 则被虚拟机认为 当flag等于1是才成立,而我们将flag改为了2,这时第一个还是不等于0,所以成立,而第一个判断语句而不等于1了所以条件不成立。
PS: 当我们把flag改为3呢,第二个条件会成立吗?
答案是:会成立,很有意思是吧,这是因为java虚拟机在内部是截取的最低位来判断的,2转换为2进制为 0010 截取最低位就是 0,而 3 转为 二进制为0001,最低位为1
另外,awk命令详细文档:https://blog.csdn.net/jiaobuchong/article/details/83037467
Docker 分为 CE 和 EE 两大版本。CE 即社区版(免费),EE 即企业版,强调安全,付费使用,这里我们使用的CE版
为了确保系统的稳定性,建议先update一下
1 | sudo yum update |
安装依赖包
1 | sudo yum install -y yum-utils device-mapper-persistent-data lvm2 |
添加docker镜像
1 | sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo |
如果官方源下载速度太慢,建议使用国内源
1 | sudo yum-config-manager --add-repo https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo |
安装docker
1 | sudo yum makecache fast |
测试是否安装成功
1 | docker run hello-world |
建立一个docker组,并将当前用户加入到此组中,这样不用root用户即可访问到 Docker 引擎的 Unix socket
1 | # 创建docker组 |
如果上面安装失败,我们可以卸载docker,重新安装
1 | sudo yum remove docker \ |
docker-compose是一个docker编排工具,它可以有效的解决我们镜像之间的依赖关系
这里提供两种方式安装:
下载docker-compose文件
1 | curl -L "https://github.com/docker/compose/releases/download/1.23.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose |
赋予文件可执行权限
1 | sudo chmod +x /usr/local/bin/docker-compose |
验证是否安装成功
1 | docker-compose version |
安装pip
1 | #安装依赖 |
安装docker-compose
1 | pip install -U docker-compose==1.23.2 |
验证安装是否成功
1 | docker-compose version |
ELKC为 elasticsearch(搜索型数据库)、logstash(日志搜集、过滤、分析)、kibana(提供Web页面分析日志)、cerebro(监控elasticsearch状态)
docker-compose.yml 文件如下
1 | version: '2.2' |
启动
1 | docker-compose up |
注意:
1、如果你看到这个提示:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least”
那说明你设置的 max_map_count 小了,编辑/etc/sysctl.conf,追加以下内容:vm.max_map_count=262144保存后,执行:sysctl -p重新启动。
2、如果启动过程中出现问题,关闭后再次启动前要先清除下数据
1 | # 停止容器并且移除数据 |
下载测试数据
http://files.grouplens.org/datasets/movielens/ml-latest-small.zip
下载Logstash
https://www.elastic.co/cn/downloads/logstash
配置logstash.conf
1 | input { |
启动logstash
1 | cd bin |
[TOC]
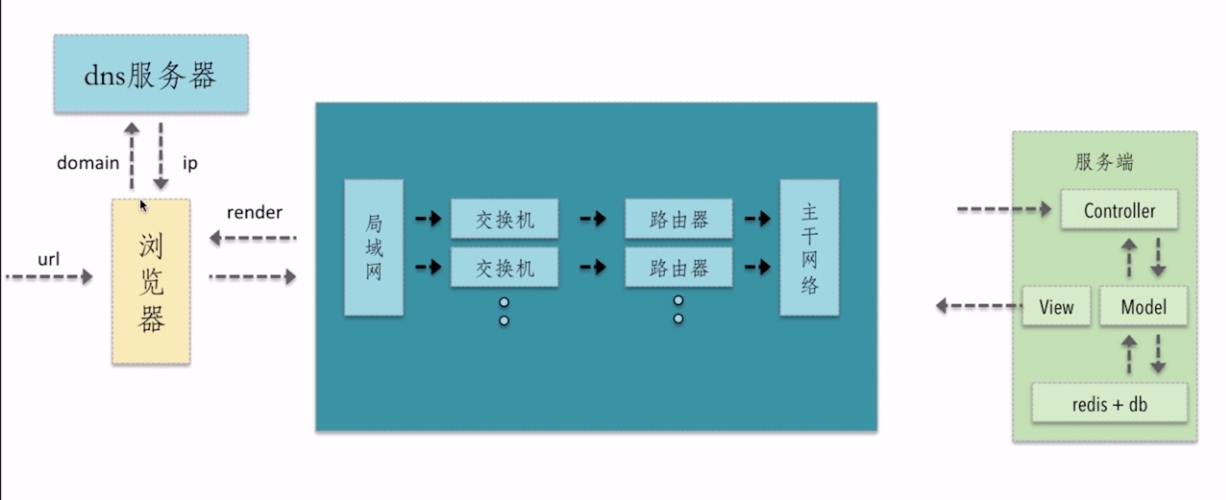
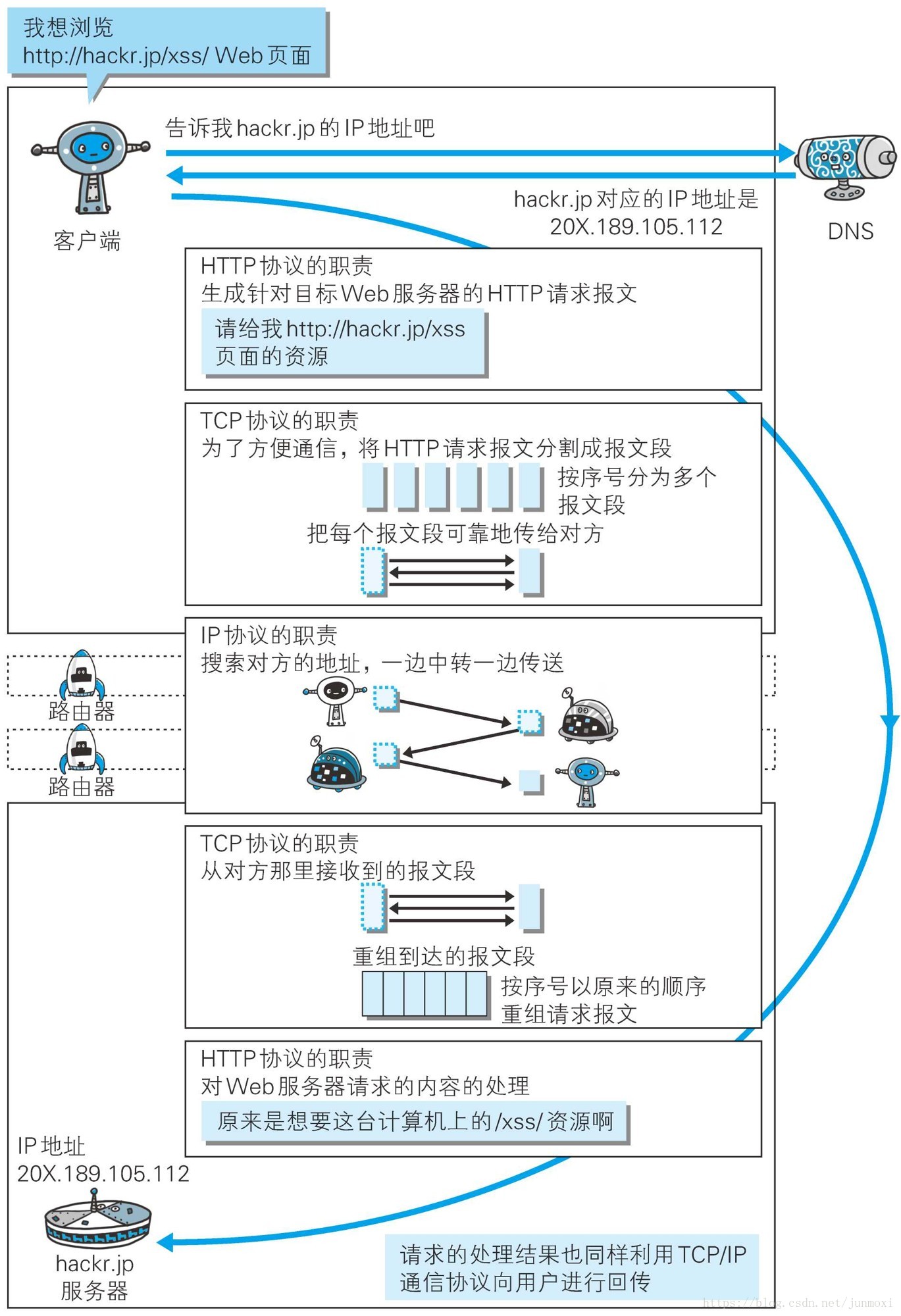
http 协议属于应用层协议,http 基于 tcp 协议,所以 client 与 server 主要通过 socket 进行通讯
用户首先在浏览器输入请求的url地址,浏览器内部的核心代码会将这个url进行拆分解析,最终将domain发送到DNS服务器上,DNS服务器会根据domain去查询相关对于的ip地址,从而将IP地址返回给浏览器,浏览器持有ip地址后就会知道这个请求是要发送到哪个地方(哪个服务器上),然后跟随协议,将ip地址打在协议中,并且请求的相关的参数都会在协议中携带,最终发送到网络中去
然后经过我们自己的局域网——交换机——路由器——主干网络——最终到达服务端
服务端是有个MVC架构的请求会首先进入到Controller中进行相关的逻辑处理和请求的分发——调用Model层(负责和数据进行交互)数据交互的过程中Model会去读取redis和数据库里面的数据——获取到数据之后叫渲染好的页面通过View层返回给网络
这时候一个HTTP请求的Response又从服务端返回到浏览器,浏览器做一个render的过程(就是根据请求回来的html以及这个html所关联的css,js去进行渲染的过程,那么渲染的过程中浏览器会根据html去形成相关的dom树以及对应的css树,然后对dom树和css树进行整合,最终知道某个dom节点知道需要什么样的样式,从而进行样式的渲染)样式渲染完成之后,浏览器会进一步去执行下面的js脚本,执行动态的页面的能力,从而最终的页面就在浏览器中展现出来了
- 序号:Seq序号,占32位,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记。
- 确认序号:Ack序号,占32位,只有ACK标志位为1时,确认序号字段才有效,Ack=Seq+1。
- 标志位:共6个,即URG、ACK、PSH、RST、SYN、FIN等,具体含义如下:
- URG:紧急指针(urgent pointer)有效。
- ACK:确认序号有效。
- PSH:接收方应该尽快将这个报文交给应用层。
- RST:重置连接。
- SYN:发起一个新连接。
- FIN:释放一个连接。
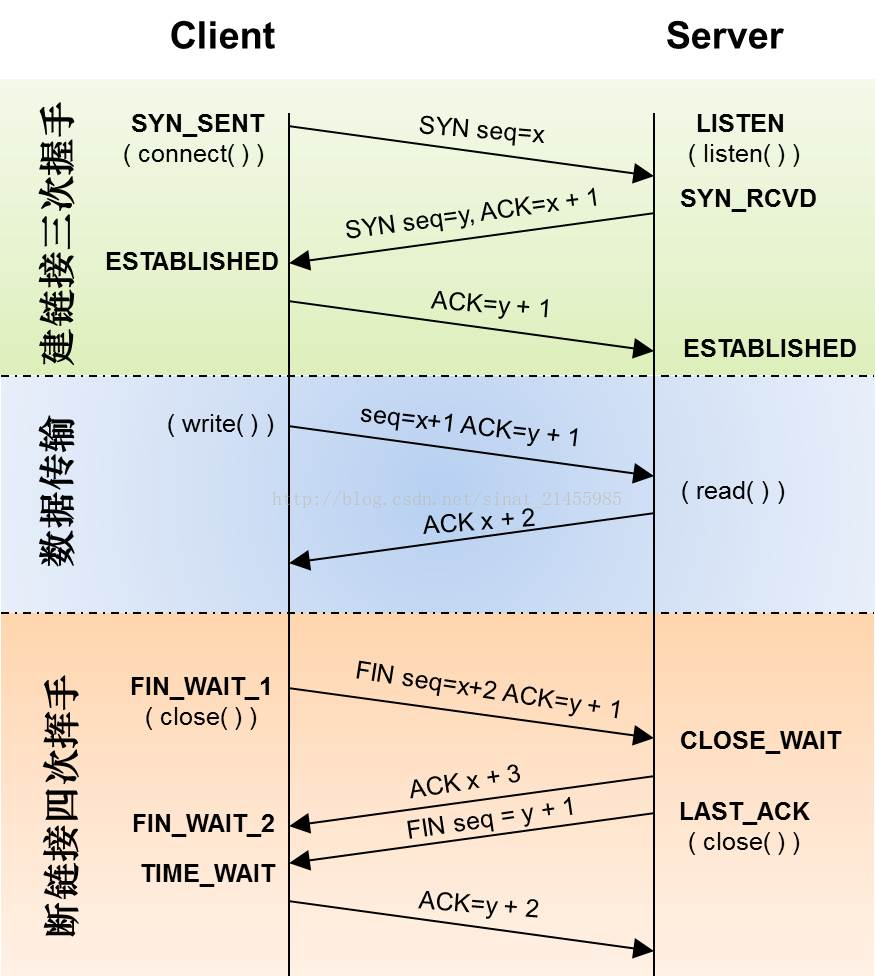
第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack (number )=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
断开连接端可以是Client端,也可以是Server端。假设Client端发起中断连接请求:
第一次挥手:客户端先发送FIN报文(第24帧),用来关闭主动方到被动关闭方的数据传送,也就是客户端告诉服务器:我已经不会再给你发数据了(当然,在fin包之前发送出去的数据,如果没有收到对应的ack确认报文,客户端依然会重发这些数据),但此时客户端还可以接受数据。
第二次挥手:Server端接到FIN报文后,但是如果还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以服务器端先发送ACK(第25帧),告诉Client端:请求已经收到了,但是我还没准备好,请继续等待停止的消息。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。
第三次挥手:当Server端确定数据已发送完成,则向Client端发送FIN报文(第26帧),告诉Client端:服务器这边数据发完了,准备好关闭连接了。
第四次挥手:Client端收到FIN报文后,就知道可以关闭连接了,但是他还是不相信网络,所以发送ACK后进入TIME_WAIT状态(第27帧), Server端收到ACK后,就知道可以断开连接了。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,最后,Client端也可以关闭连接了至此,TCP连接就已经完全关闭了!
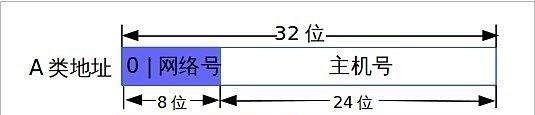
A、B、C、D、E五类地址
- A类地址由政府机构使用。
区别:A类地址的第1字节是网络的地址,其它的3个字节为主机的地址。
A类地址范围为:1.0.0.1-126.255.255.254。
- B类地址有中等等级公司使用。
区别:B类地址的第1字节和第2字节是网络地址,其它2个字节为主机的地址。B类地址范围:128.0.0.1—191.255.255.254。
- C类地址分配给需要的个人。
区别:C类地址第1字节、第2字节和第3个字节为网络地址,最后一个字节为主机地址。并且第1个字节的前三位都是110。C类地址范围:192.0.0.1—223.255.255.254。
- D类地址用于组播。
区别:D类地址不分网络地址和主机地址,但它的第1个字节的前四位都是1110。D类地址范围:224.0.0.1—239.255.255.254
- E类地址用于实验。
区别:E类地址也不分网络地址和主机地址,但它的第1个字节的前五位都是11110。E类地址范围:240.0.0.1—255.255.255.254
202.112.78.0 是个C类IP 前3位为网络位 最后一位是主机位
子网掩码是255.255.255.192(11111111.11111111.11111111.11000000)
说明 向主机位借2位
(11000000 11为子网 000000为主机)
所以 n = 2 ,m = 6
2的n次方-2 = 可划分的子网数
n=2 所以可以划分2个子网
2的m次方 - 2 = 每个子网的主机主机数
又因为m=6
- 利用子网数来计算
在求子网掩码之前必须先搞清楚要划分的子网数目,以及每个子网内的所需主机数目。
1)将子网数目转化为二进制来表示
2)取得该二进制的位数,为 N
3)取得该IP地址的类子网掩码,将其主机地址部分的的前N位置 1 即得出该IP地址划分子网的子网掩码。
如欲将B类IP地址168.195.0.0划分成27个子网:
1)27=11011
2)该二进制为五位数,N = 5
3)将B类地址的子网掩码255.255.0.0的主机地址前5位置 1,得到 255.255.248.0
即为划分成 27个子网的B类IP地址 168.195.0.0的子网掩码。
- 利用主机数来计算
1)将主机数目转化为二进制来表示
2)如果主机数小于或等于254(注意去掉保留的两个IP地址),则取得该主机的二进制位数,为 N,这里肯定 N<8。如果大于254,则 N>8,这就是说主机地址将占据不止8位。
3)使用255.255.255.255来将该类IP地址的主机地址位数全部置1,然后从后向前的将N位全部置为 0,即为子网掩码值。
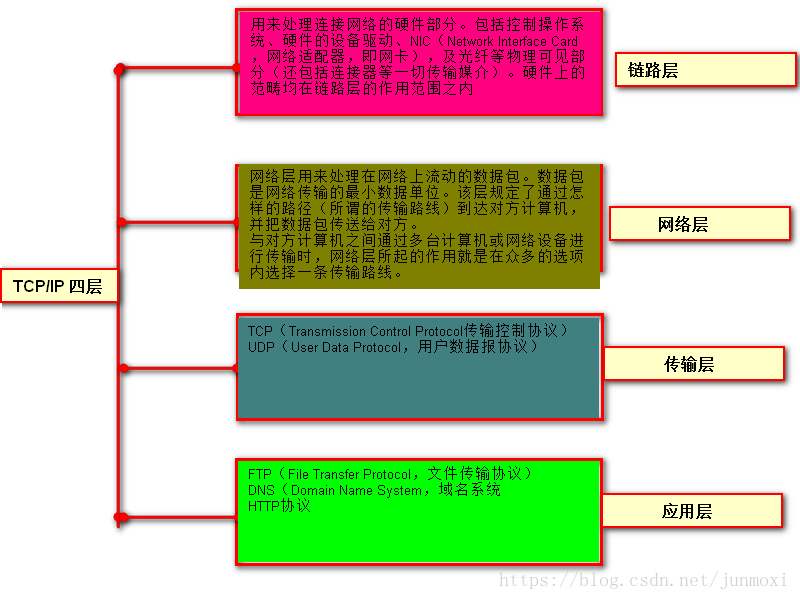
TCP/IP协议是一个协议集合。大家叫的时候方便说,所以统称为TCP/IP。TCP/IP协议族中有一个重要的概念是分层,TCP/IP协议按照层次分为以下四层。应用层、传输层、网络层、数据链路层。为什么要分层?这就如同邓小平1978年的大包干,责任到人。一个层只负责一个层次的问题,如果出问题了,和其他的层次无关,只要维护这个层次也就好了。其实编程语言里也能体现这个分层理论,即封转性、隔离。
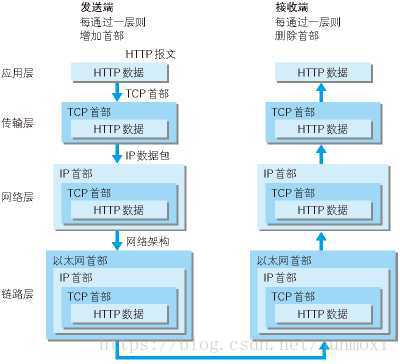
TCP/IP通信数据流
属于网络层
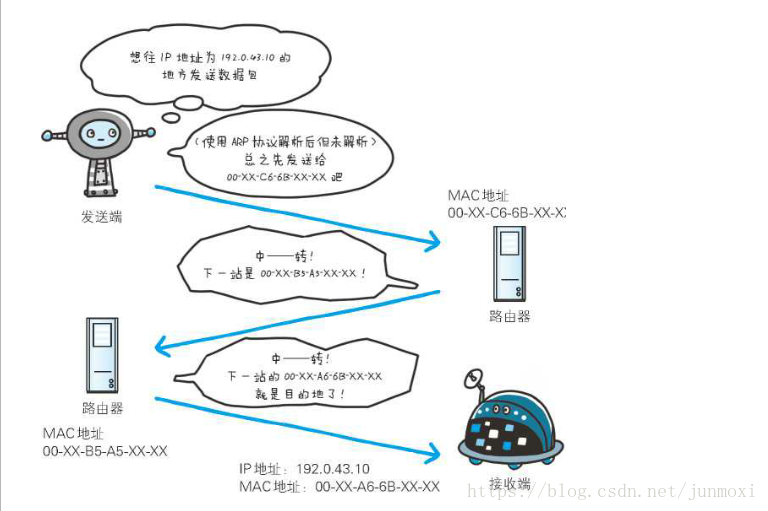
IP协议:IP(Internet protocol),这里的IP不是值得我们通常所说的192.168.1.1.这个IP指的是一种协议,而后面的数字值得是IP地址。IP协议的作用在于把各种数据包准确无误的传递给对方,其中两个重要的条件是IP地址,和MAC地址(Media Access Control Address)。由于IP地址是稀有资源,不可能每个人都拥有一个IP地址,所以我们通常的IP地址是路由器给我们生成的IP地址,路由器里面会记录我们的MAC地址。而MAC地址是全球唯一的,除去人为因素外不可能重复。举一个现实生活中的例子,IP地址就如同是我们居住小区的地址,而MAC地址就是我们住的那栋楼那个房间那个人。
属于数据链路层
使用 ARP 协议凭借 MAC 地址进行通信
IP 间的通信依赖 MAC 地址。在网络上,通信的双方在同一局域网(LAN)内的情况是很少的,通常是经过多台计算机和网络设备中转才能连接到对方。而在进行中转时,会利用下一站中转设备的 MAC 地址来搜索下一个中转目标。这时,会采用 ARP 协议(Address Resolution Protocol)。ARP 是一种用以解析地址的协议,根据通信方的 IP 地址就可以反查出对应的 MAC 地址
属于传输层
如果说IP协议是找到对方的详细地址。那么TCP协议就是把安全的把东西带给对方。各有分工,互不冲突。
按层次分,TCP属于传输层,提供可靠的字节流服务。什么叫字节流服务呢?这个名字听起来让人不知所以然,下面听下我通俗的解释。所谓的字节流,其实就类似于信息切割。比如你是一个卖自行车的,你要去送货。安装好的自行车,太过庞大,又不稳定,容易损伤。不如直接把自行车拆开来,每个零件上都贴上收货人的姓名。最后送到后按照把属于同一个人的自行车再组装起来,这个拆解、运输、拼装的过程其实就是TCP字节流的过程。
用漫画来表示三次握手
属于应用层
DNS:DNS(Domain names System) 和HTTP协议一样是处于应用层的服务,提供域名到IP地址之间的解析服务。
互联网之间是通过IP地址通信的,但是IP地址并不符合认得记忆习惯,人喜欢记忆有意义的字词。所以DNS服务就为了解决这个问题而生了。其实很好理解,形如我们电脑中host文件,当我们添加下面一句配置后:
192.168.1.11 roverliang.com
当我们访问roverliang.com 的时候,电脑便不会去外网服务器上查询了,直接去访问192.168.1.111。这是一个简单的域名劫持,足以说明DNS的涵义了。
用一个漫画表示DNS解析过程
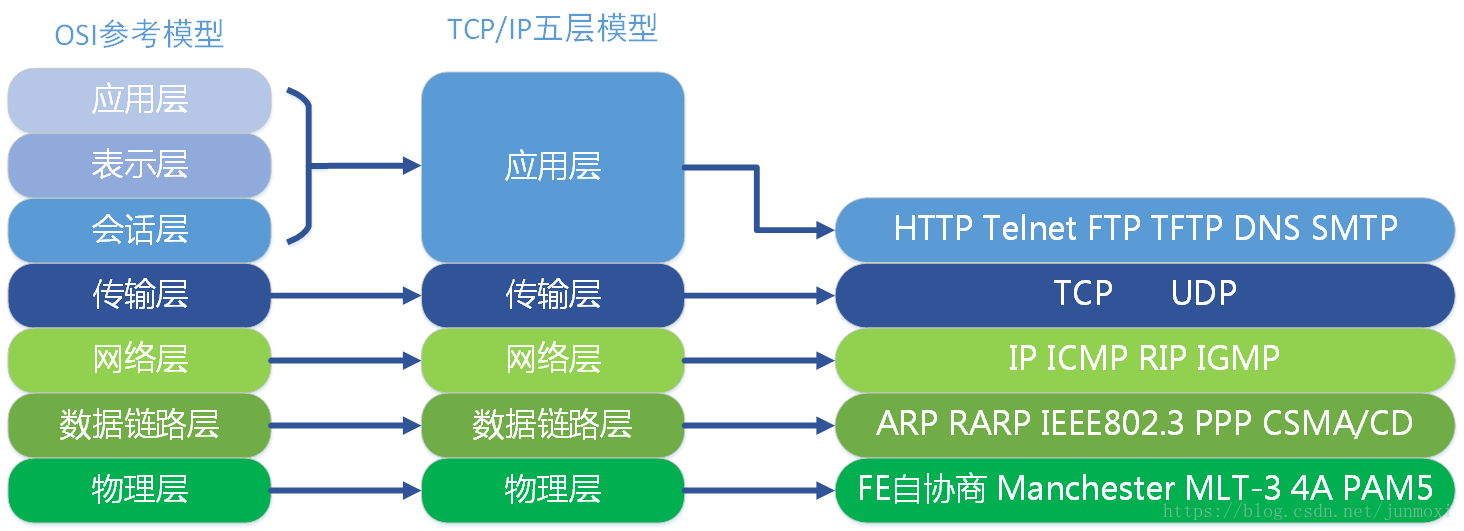
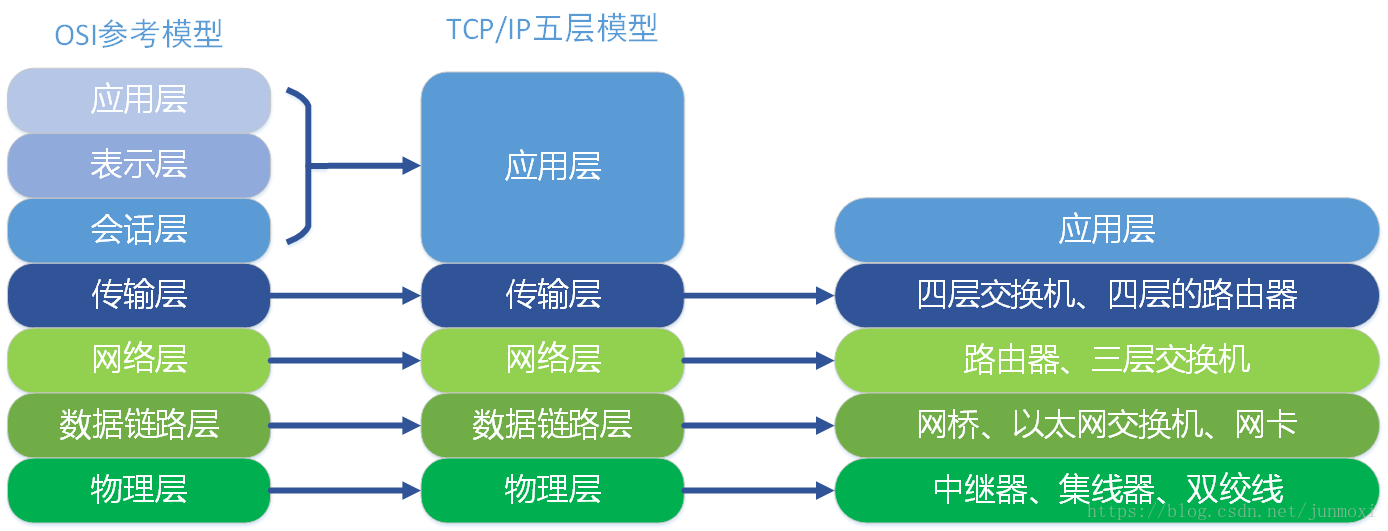
*TCP/IP五层模型: *
OSI模型:
对应关系:
对应的协议
对应的设备
本文采用沙箱环境
文档:https://docs.open.alipay.com/200/105311/
沙箱地址:https://openhome.alipay.com/platform/appDaily.htm
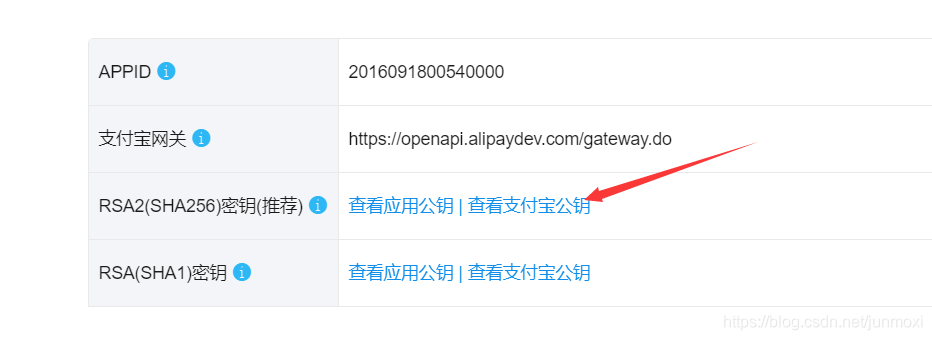
本文中的签名方法默认为 RSA2,采用支付宝提供的 RSA签名&验签工具 生成秘钥时,秘钥的格式必须为 PKCS1,秘钥长度推荐 2048。所以在支付宝管理后台请注意配置 RSA2(SHA256)密钥。
生成秘钥对之后,将公钥提供给支付宝(通过支付宝后台上传)对我们请求的数据进行签名验证,我们的代码中将使用私钥对请求数据签名。
RSA签名和验证工具下载:https://docs.open.alipay.com/291/105971
RSA签名验签工具.batPKCS1
目前新创建的支付宝应用只支持证书方式认证,已经弃用之前的公钥和私钥的方式
公钥秘钥说明
我们生成秘钥对之后,将公钥提供给支付宝(通过支付宝后台上传)对我们请求的数据进行签名验证,我们的代码中使用私钥对请求数据签名。
下载地址与文档:https://docs.open.alipay.com/291/105971
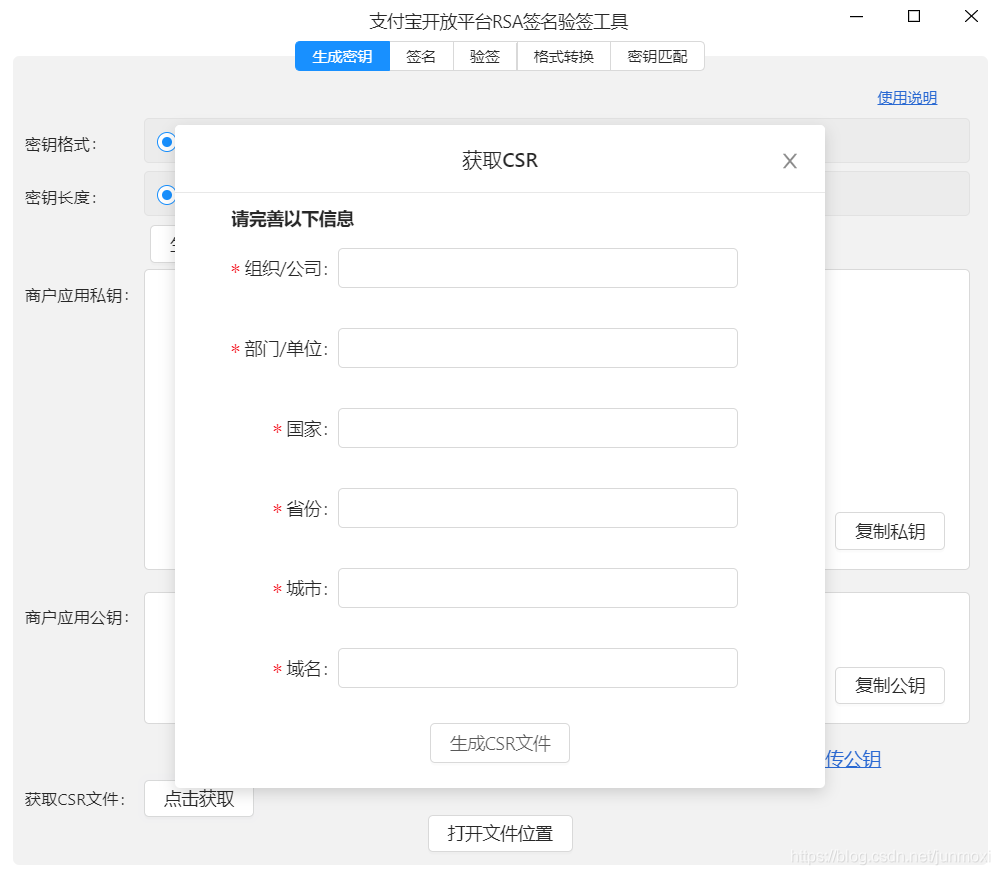
工具安装好之后打开,点击获取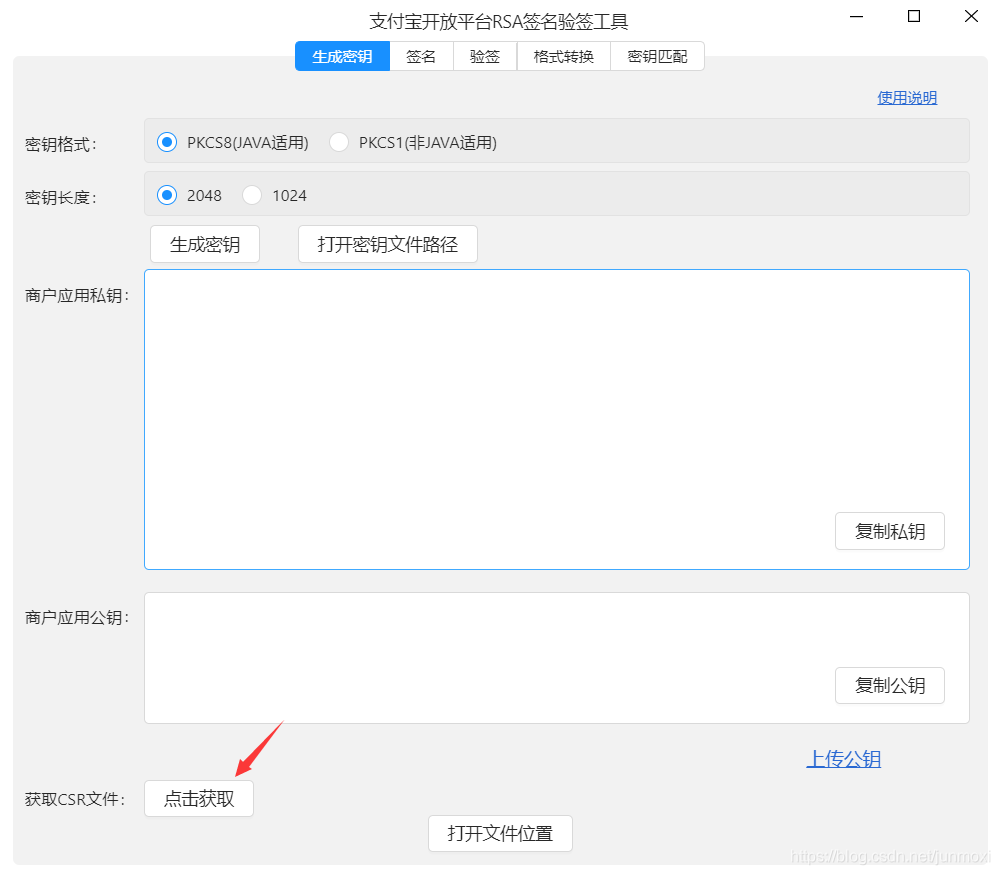
主要是组织/公司这块一定要写的和你支付宝中应用的名一样,不然不会通过的,填写完毕之后点击
生成CSR文件,点击页面的打开文件位置,就可以看到三个文件了,分别是证书签名请求文件,应用公钥,应用私钥
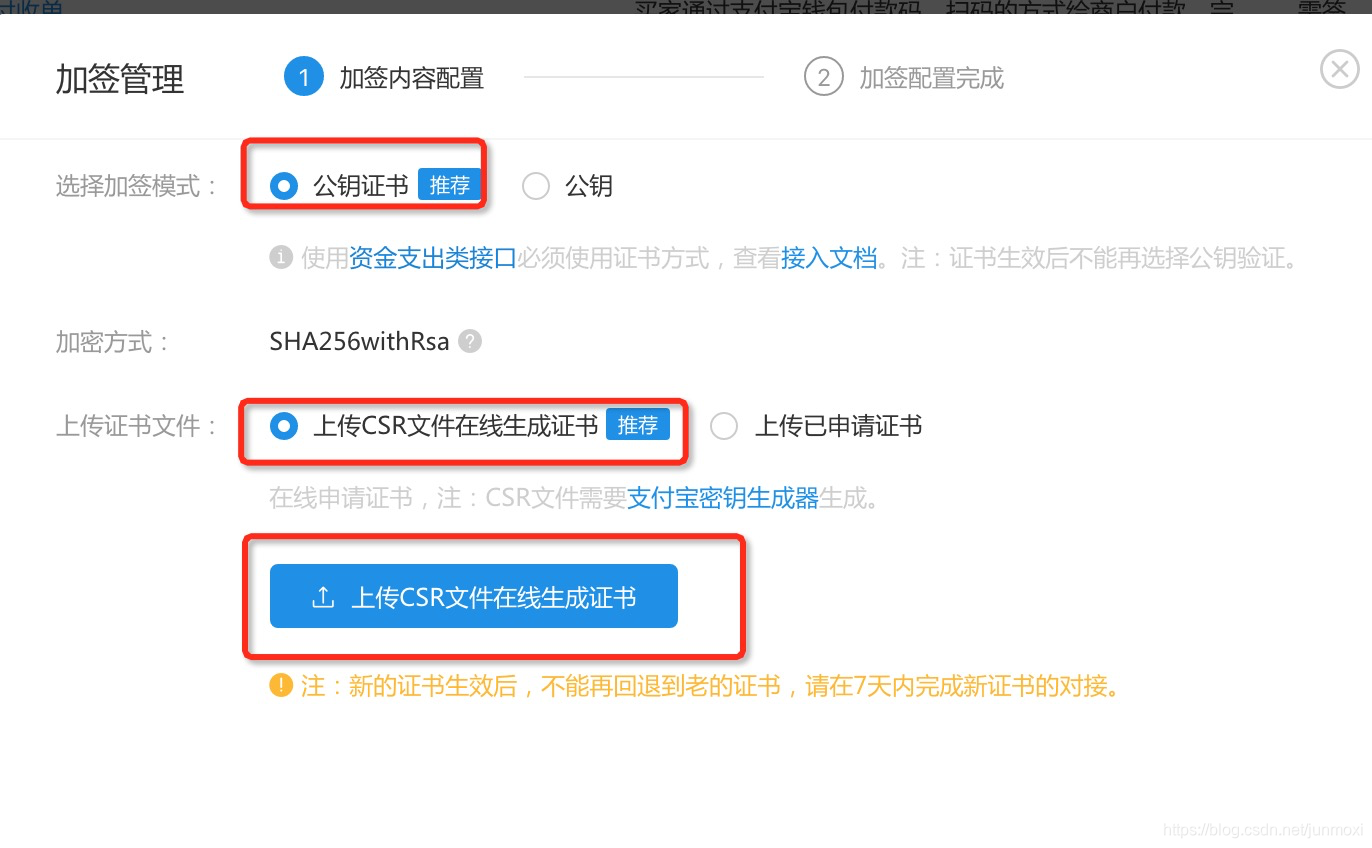
回到支付宝后台,点击
接口加签方式设置,选择公钥证书,点击上次CSR生成证书,把我们刚才生成的那个证书(.csr)上传进去
上传好之后,会弹出让你下载证书的页面,把那三个证书都下载下来,分别是: 应用公钥证书,支付宝公钥证书,支付宝根证书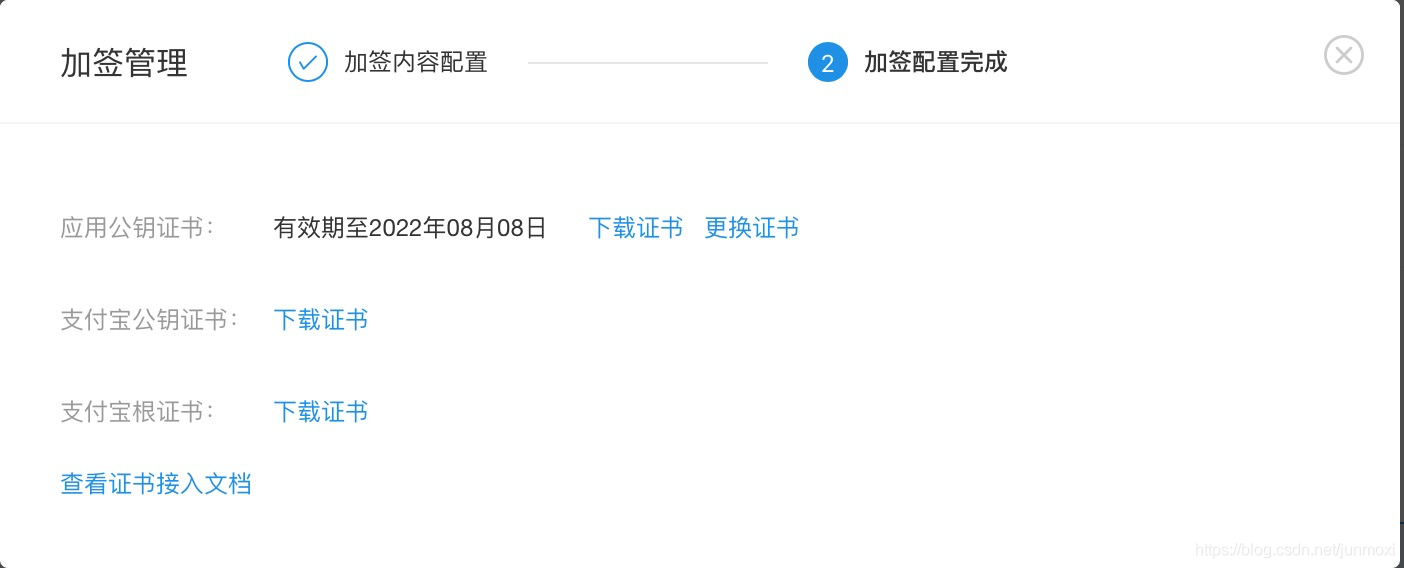
下载第三方库go get github.com/smartwalle/alipay/v3
1 | package main |
环境:Centos、JDK1.8
点击查看官网详细安装
安装稳定版,依次执行下面语句:
1 | sudo wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins-ci.org/redhat-stable/jenkins.repo |
查看当前JDK安装路径
1 | echo $JAVA_HOME |
修改Jenkins启动时搜索的JDK路径
1 | vi /etc/rc.d/init.d/jenkins |
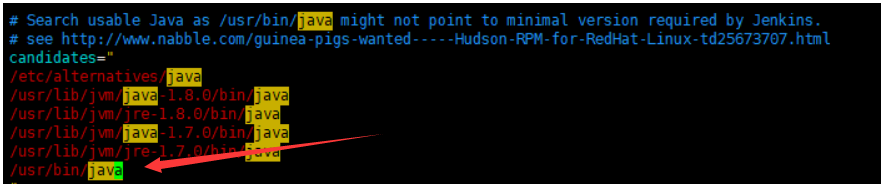
将这个改为你的JDK路径,也就是echo $JAVA_HOME输出的内容加上 /bin/java
1 | vi /etc/sysconfig/jenkins |
将JENKINS_PORT=”8080”修改为JENKINS_PORT=”9000”
1 | service jenkins restart |
打开http://你的ip:9000开始布置Jenkins